ニューラルネットワークでは線形変換+活性化関数で一層という考え方が基本になります。
線形変換を行うAffine/Convolutionに対して、ニューラルネットワークの表現力を向上するための非線形変換を行う活性化関数について改めて紹介します。
Sigmoid
入力値を0.0~1.0に確率的に収める。2値分類問題では、BinaryCrossentropyで出力と正解の要素ごとのロスを計算する。
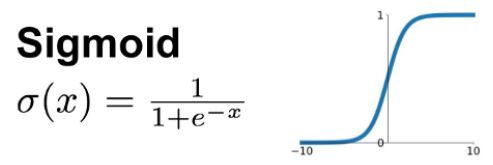
滑らかで微分可能な関数であるが、微分すると値は0以上0.25以下となる(1以下である)ため層を重ねると勾配消失問題が起こる。
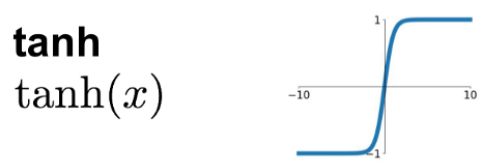
Tanh
シグモイドに近いが、-1.0~1.0の値域をとり原点0を通る。昔よく使われていたが、入力値の絶対値が大きくなると最適化が進みづらくなるため、中間層には用いられなくなった。
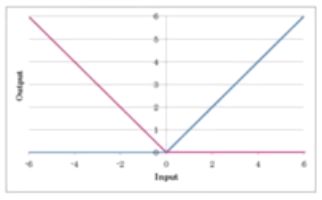
ReLU
計算コストが軽く現状最も利用されている活性化関数。常に勾配が1でシグモイド関数の勾配消失問題を軽減できる。入力値が大きい場合も0以上であればそのまま出力し、0以下は0となりスパース性につながる。複雑な関数も折れ線で近似していくイメージ。
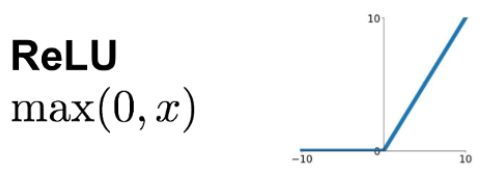
特に画像を表現する画素値はunsigned intであるため、ReLUは理にかなっています。
LeakyReLU
xが0以下の場合に微分係数が常に0となり誤差が逆伝播しない問題を改善したReLU。負の値を入力するときの傾きはハイパパラメータとして指定する必要がある。

PReLU
ParametricReLU。LealyReLUの負の傾きの大きさも自体もニューラルネットワークのパラメータの学習に含めるたもの
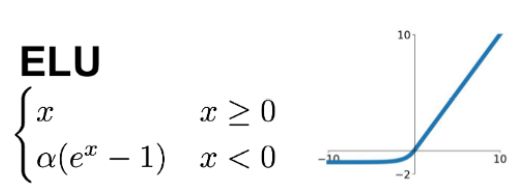
ELU
0付近でも滑らかに勾配を変化させる。Softplus,SELUも似た関数の形をもつ。
CReLU
Convolutionの結果の符号反転した結果を得ることができ、フィルタ数のバリエーションを増やすに等しい効果がある(最大2倍)。
論文:https://arxiv.org/pdf/1603.05201.pdf
Swish
強化学習により発見された、高い性能を実現する活性化関数。入力値にシグモイド関数の出力を掛け合わせたもの。既存の活性化関数を置き換えると多くのケースで性能向上が見られたと報告されている。

論文:https://arxiv.org/pdf/1603.05201.pdf
Softmax
入力値を出力の合計が1.0となるように、0~1.0の間の実数として確率的に収める。クラス分類で各クラスに属する確率を出力し、正解カテゴリIndexとのクロスエントロピーを計算するのに用いられる。
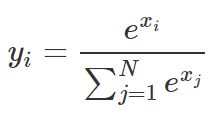
上記の式では、出力がN個あるとしてi番目の出力yiを求める式を表しています。
まとめ
入力の値は?
極力、活性化関数の入力には-1.0~1.0の範囲に収まるようにしたいので、入力も前処理で正規化しておく。(例:RGBなど0~255→0~1に正規化する)
中間層の活性化関数は?
まずは計算の軽いReLUで試すべし。行き詰まったら他の活性化関数を息抜きに試してみてもよいが、周りの報告からはそこまで大きな効果は期待できないかも。
出力層の活性化関数は?
二値分類問題→Sigmoid
多クラス分類問題→Softmax
回帰問題→活性化関数なし(恒等関数)が一般的
図など参考記事: