
タイトルがしょうもないって?
本日は画像変換のアルゴリズムについてまとめます。Deep Learningを活用した画像変換の動向として、やはりGANなしでは語れません。
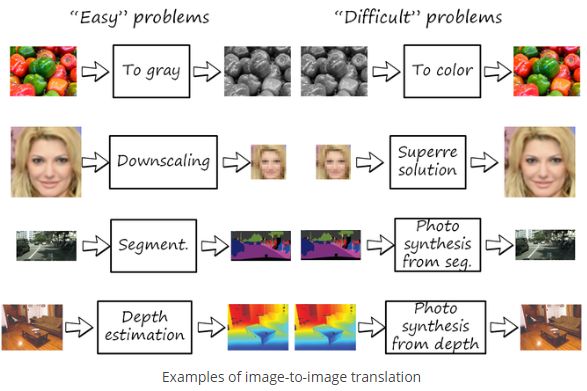
画像変換のジャンル分け
GANを使った画像変換の入力-出力の対応とアルゴリズムをまとめてみます。
| Uni-modal(1:1) | Multi-modal(1:N) | |
| 教師あり | Pix2Pix | BicycleGAN |
| 教師なし | CYcleGAN, DiscoGAN, UNIT | StarGAN, MUNIT, DRIT |
Uni-modalとは1対1の画像変換のことでMulti-modalは1対多の画像変換を行います。
Pix2Pixは画像変換において最も基本となる学習アルゴリズムで、1対1のペアの画像入力の返還を行います。たとえば簡易地図/航空写真の変換や白黒画像/カラー画像の変換など、正解ペアを大量に用意できるケースに適しています。ゆえに教師あり学習といわれます。
一方で、馬/シマウマの変換のように多対多で画像を用意できるものの、きれいな1対1のペアの画像が用意できないケースは教師なし学習でCycleGANが基準のアルゴリズムとなります。
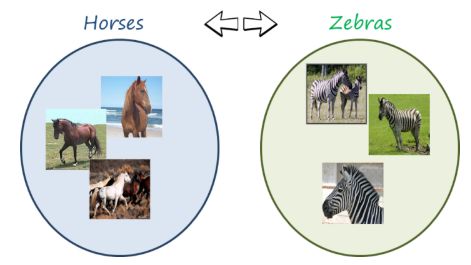
教師なしの画像変換といえばCycleGAN
多くのGANでは学習時にDiscriminatorの穴をついた出力をGeneratorが学習してしまい同じ画像の出力をし続けるMode collapse問題に悩まされます。CycleGANではCycle-consistency lossを導入したことでmode collapseに陥ることを防ぎつつ、Identity lossによって入力の色・形を維持することが可能になりました。

さらに、CycleGANでは形を維持したデータの学習を得意としますが、DiscoGANでは形状の違いすらも学習時に吸収することができます。二つの学習におけるDiscriminatorのReceptive field(見ている範囲)の差がこのような違いを生んでいます。(例:256×256 VS 64×64)
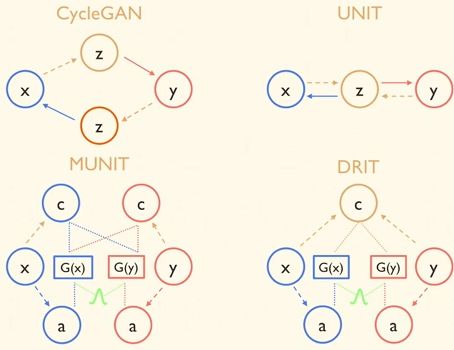
CycleGANの派生:マルチモーダルドメイン変換
| 種別 | CycleGANとの違い | 特徴 |
| StarGAN | Conditionの追加(CycleGAN + ACGAN) | ・変数が少ない |
| UNIT | 潜在空間の重み共有 | ・変数が少ない |
| MUNIT | コンテンツ&スタイル分離 | ・マルチモーダル変換 |
| DRIT | UNIT + MUNIT | ・変数が少ない
・マルチモーダル変換 |
StarGANはCycleGANの入力にconditionを追加して、Generatorでは変換先の画像を指定し、DiscriminatorではそのClass判別も学習する工夫(ACGAN)をしています。これにより多対多のマルチドメイン変換であっても複数のGenerator/Discriminatorを持つ必要がなくなります。
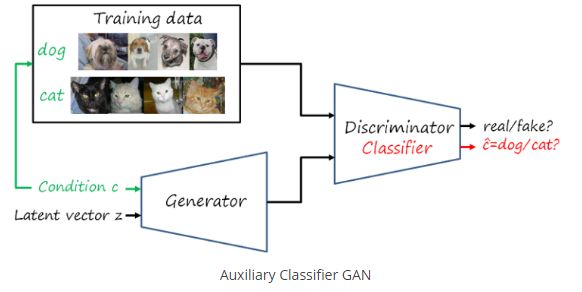
(http://www.lherranz.org/2018/08/07/imagetranslation/)
ネットワークアーキテクチャの概略図
(編集途中)