概要
Deep Learningでは訓練データを学習する際は一般にミニバッチ学習を行います。
学習の1ステップでは巨大なデータセットの中から代表的なデータを一部取り出して、全体データの近似として損失の計算に使います。バッチことに平均の損失を計算することで、データ数に関係なく統一した学習をすることが狙いです。本記事ではニューラルネットワークの学習安定化を図るためのバッチ正規化手法“Batch Normalization”について議論します。
学習時の重みの初期値の重要性
勾配消失・過学習などに陥って学習に失敗した際、様々なことが要因のして考えられますが中でも見落としがちなのが重みの初期値です。各層の活性化関数の出力の分布は適度な広がりを持つことが求められます。適度に多様性を持ったデータが流れたほうが効率的な学習ができますが、偏ったデータが流れると勾配消失が起きる場合があります。そこで、初期値にそこまで神経質にならくていいように
各層の出力の分布の広がりをうまく調整できないか?
という発想のもとBatch Normalizationではこの問題に対応します。
Batch Normalizationとは
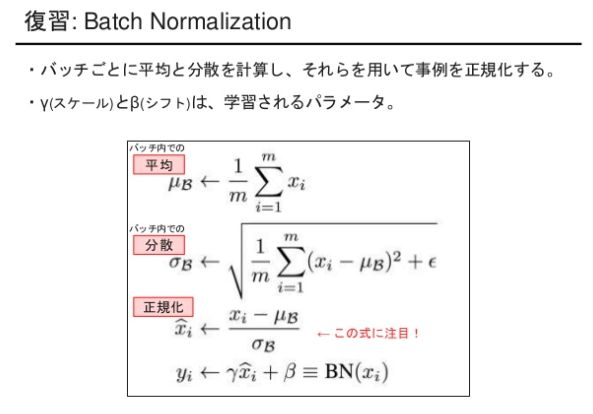
その名の通り学習時のミニバッチごとに、平均0分散1となるように正規化を行うアイデアです。学習の安定性を高めるだけでなく学習を早く進行させることもでき、近年のDeep Learningでは必須のテクニックです。しかし、バッチサイズが大きいと計算のためにその分大きなメモリが必要になります。メモリが限られている場合でも複数GPUに跨って平均/分散の推定を行うことで対応することも可能ですが実装の難易度が上がります。
詳細な説明をしている以下のページが非常にわかりやすいです。
参考:https://qiita.com/t-tkd3a/items/14950dbf55f7a3095600

特に、CNNの場合はConv出力のチャンネルをシリアライズして全結合と同じ考え方で計算できます。

前の層のチャンネルごとに4つのパラメータがあり、バッチ平均・分散(μ,σ)は入力データのバッチから導出され、スケール・シフト(γ,β)は訓練パラメータとなり、入力データに正規化を適応して出力します。
様々な派生があるがどの正規化を使うべきか?
有名どころはこの辺りです。
- Batch Normalization
- Layer Normalozation
- Instance Normalization
- Group Normalization
さて、それぞれどんな場面でどの手法を使うのがベストなのでしょうか。
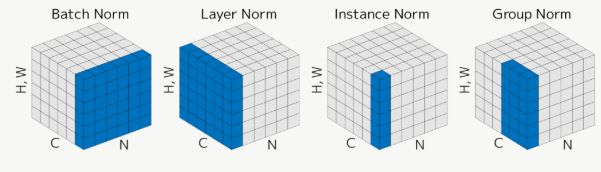
( N:batch size, C:channel, H:image height, W: image width )
参考:http://mlexplained.com/2018/11/30/an-overview-of-normalization-methods-in-deep-learning/
代表的なNormalization手法が図の通りで、平均と分散を計算する領域がそれぞれ異なっています。各手法では図の青色で示す領域ごとに平均と分散を計算します。
最もシンプルなのは、各チャンネル独立に画像の縦横方向についてのみ平均・分散を取る Instance Normalizationです。ちなみにBatch Normalizationのバッチサイズが1の場合、Instance Normalizationと等価です。バッチサイズが十分に確保できない場合の対策として、全チャンネルに跨って平均・分散をとるのがLayer Normalizationです。さらに、チャンネルをグループに分けてLayer NormとInstance NormのいいとこどりをしたのがGroup Normalizationというイメージです。
基本的にはBatch Normalizationを実践では第一候補としましょう。
参考:https://blog.albert2005.co.jp/2018/09/05/group_normalization/
Instance Normalizationの使いどころ
ネットワークが元画像のコントラストに依存しない学習をすることができるため、スタイル変換などのタスクに適しているといわれています。画像認識では非常に価値がありますが、RNNでは価値を発揮できなさそうです。GANのスタイル変換タスクにおいても、Batch Normalizationに置き換えて使用されるケースを見かけます(例:StarGAN)。Batch normと違い、バッチとしてではなくデータごとに平均・分散を計算すればよいため、学習中に移動平均(μ, σ)を計算する必要はありません。学習すべき重みは無くてもよい、あるいはオプションでスケーリング(γ)シフト(β)だけあればいいことになります。
Batch Normalizationの弱点
理想的にはミニバッチごとの平均ではなく、データセット全体の平均(global mean)と分散(global variance)を使って正規化したいです。Batch normalizationでバッチサイズが非常に小さいと、結局ミニバッチごとにばらつきが大きくなり学習が不安定になります。
応用編
追加で評判の良い以下の3つの正規化手法も簡単にご紹介します。
- Batch Renormalization
- Switchable Normalization
- Batch-Instance Normalization
- Spectral Normalization
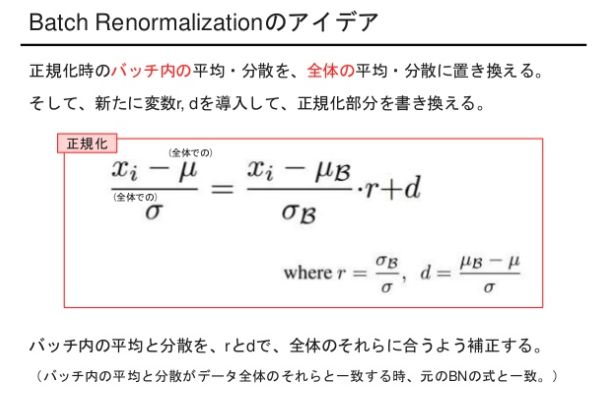
Batch Renormalization
Batch Normでは学習時に全体の統計量をもとに正規化をすると勾配爆発に陥ってしまいます。そこで、ミニバッチごとの移動平均ではなく母平均を使うことで、本当の全体データセットの平均・分散に近い推定ができるというアイデアです。バッチサイズが小さいときでも、学習時と推論時の誤差を小さくすることができます。
Batch-Instance Normalization
Instance Normalizationでは完全にスタイル情報を消し去ってしまうという弱点があります。スタイル変換では問題ないのですが、例えば天気のクラス分類のようにスタイル情報が重要視されるべき問題のときには致命的です。そこで、解くタスクや特徴マップの出力として、スタイル情報をどれだけ重視すべきかを学習するためにBatch-Instance Normalizationというアイデアが活躍します。下式のように、Batch normとInstance normのバランスパラメータρも学習させ、2つの正規化を組み合わせることで単純なBatch normを上回る性能を実現することができます。
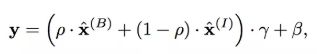
[GAN向け]Spectral Normalization
GANの学習では、Discriminatorが学習しすぎると誤差がGeneratorにうまく伝播されなくなってしまいます。Spectral Normalizationは、リプシッツ連続(入力xからyへの変化に対する出力F(x)からF(y)への変化の割合の最大値が一定数以下のとき、関数Fはリプシッツ連続)を重要視したNormalizationであり、層毎にSpectral Normを制限することでDiscriminatorのリプシッツ定数(リプシッツ連続のときの最大変化量)を制御する手法になります。GANの学習バランス崩壊の対策としてDiscriminatorの出力を緩やかに変化させるためにDiscriminatorにのみ導入します。
![]()
Adaptive Instance Normalization
StyleGANやスタイル変換の学習時の正規化によく使われている手法です。通称AdaInと呼ばれています。Instance Normalizationの発展という位置づけになりますが、正規化時の係数とバイアスにstyle画像の平均と標準偏差を用います。例えば、画風変換タスクであれば、contents画像に対してstyle画像の係数とバイアスを使うというシンプルなアイデアに基づきます。
SPADE
例えば画像生成タスクにおいてセグメンテーションマスクを入力として与え、マスクラベルごとにβ、γを計算してelement-wiseに正規化を行う手法。通常の正規化では空間不変となるが、SPADEでは位置によって異なるβ,γを使用するためマスクの意味情報を考慮することができる。