図:TUNIT
2020年8月1日現在、画像変換タスク(Image-to-Image translation)の研究で新しめのものをピックアップする。多くはCycleGAN [ICCV2017]から派生した教師なしのGAN、UNIT [NIPS2017]から派生したshared latent spaceやVAEの考え方を導入したアルゴリズムとなっている。
簡素な説明と、ネットワークアーキテクチャの概略図を論文から引用して載せている。
StarGAN [CVPR2018]
“StarGAN: Unified Generative Adversarial Networks for Multi-Domain Image-to-Image Translation”
CycleGANにconditionを導入して、単一のGeneratorでマルチドメイン変換を実現した。Discriminatorでは入力画像の真偽だけでなくクラス判別も学習する(ACGAN)。

MUNIT [ECCV2018]
“Multimodal Unsupervised Image-to-Image Translation”
犬↔猫のようなドメインの変換を実現。CycleGANでは単一種類への変換しか学習できなかったが、Style/content特徴に分離することで猫の種類(style feature)をコントロールしてマルチモーダルな変換までできる。スタイル特徴はデコーダ側でAdaINを使って取り込む。
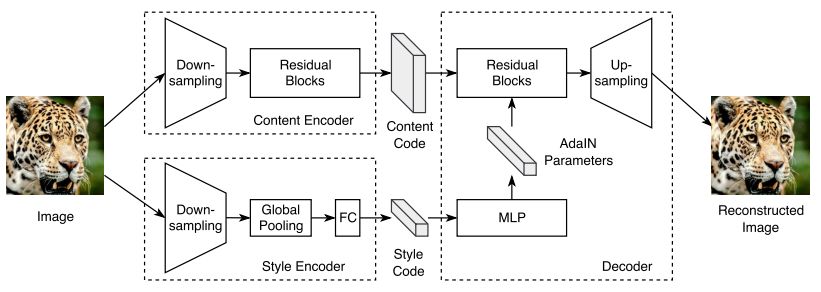
DRIT [ECCV2018]
“Diverse Image-to-Image Translation via Disentangled Representations “
MUNITに似ているが、attribute/contentをともに共通の特徴空間に写像する。そのためにcontent adv/ domain adv/ KL loss/ Cross-cycle consistency lossなど用いる。最新版(DRIT++)では、後に紹介するMSGANのmode-seeking regularizationを導入することでmode collapse問題を改善している。
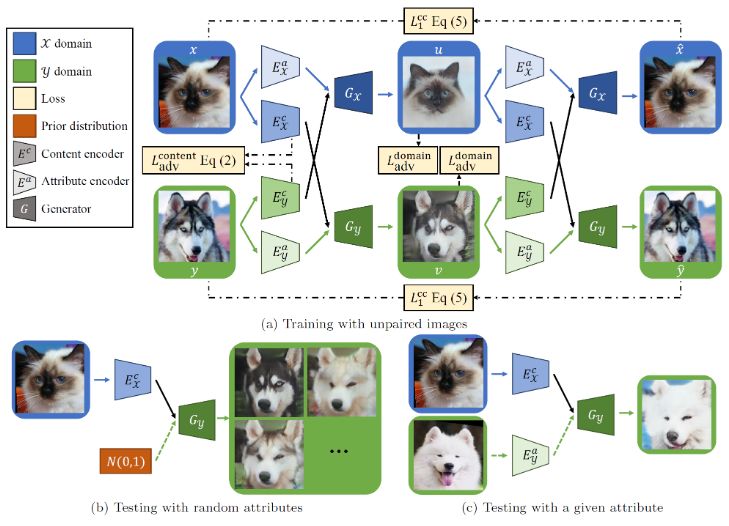
FUNIT [ICCV2019]
“Few-Shot Unsupervised Image-to-Image Translation”
MUNITではドメインごとに大量の画像データを用意する必要があった。これに対して、テスト時に数枚のサンプルしかない未知のドメインに対しても画像変換を可能にした。ただ、学習時には多種類のドメインを用意して膨大なデータを学習する必要があるため使いどころが難しそうな印象。
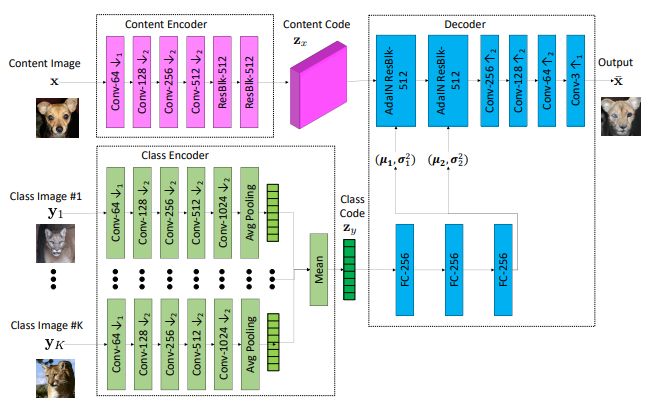
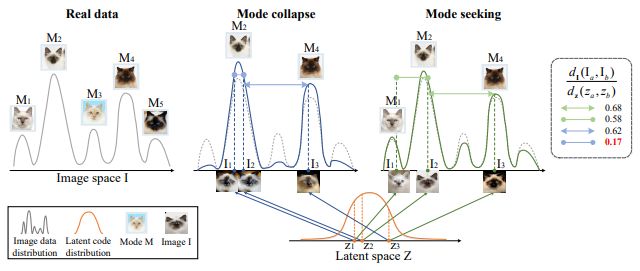
MSGAN [CVPR2019]
“Mode Seeking Generative Adversarial Networks for Diverse Image Synthesis”
StarGANなどのconditionalGANベースの手法では多様性をキープするのが難しい。特定の出力ばかりに偏ってしまうMode Collapseを防ぐため、latent spaceの入力変化に対する生成画像変化を考慮したmode seeking regularizationを導入。幅広いドメイン表現の学習を可能にした。
TransGaGa [CVPR2019]
“TransGaGa: Geometry-Aware Unsupervised Image-to-Image Translation”
形状が大きく異なる二つのドメイン変換の学習。appearance(見た目)とgeometry(向き)の情報をそれぞれのエンコーダにより分離し、conditional VAEベースで学習させる。

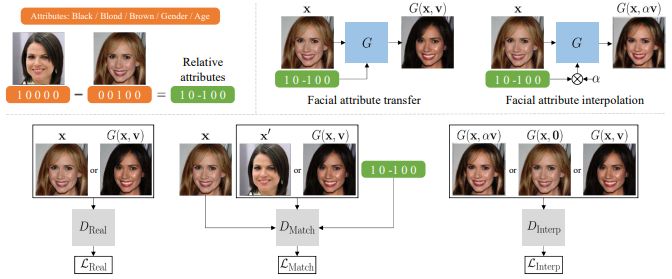
RelGAN [ICCV2019]
“RelGAN: Multi-Domain Image-to-Image Translation via Relative Attributes”
StarGANではバイナリ(0か1)でドメイン属性を指定していた。RelGANでは相対的な属性変化を学習させて、例えば笑顔の度合を調整(0.5など中途半端な値に設定)して変換することができる。
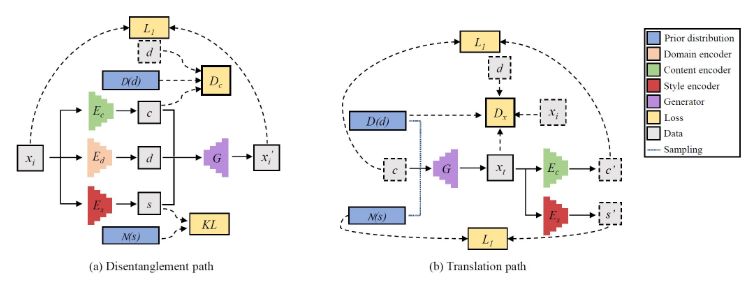
DMIT [NeurIPS 2019]
“Multi-mapping Image-to-Image Translation via Learning Disentanglement”
過去の研究ではいずれかしか行っていなかった、マルチモーダル変換とマルチドメイン変換を同時に学習させる。
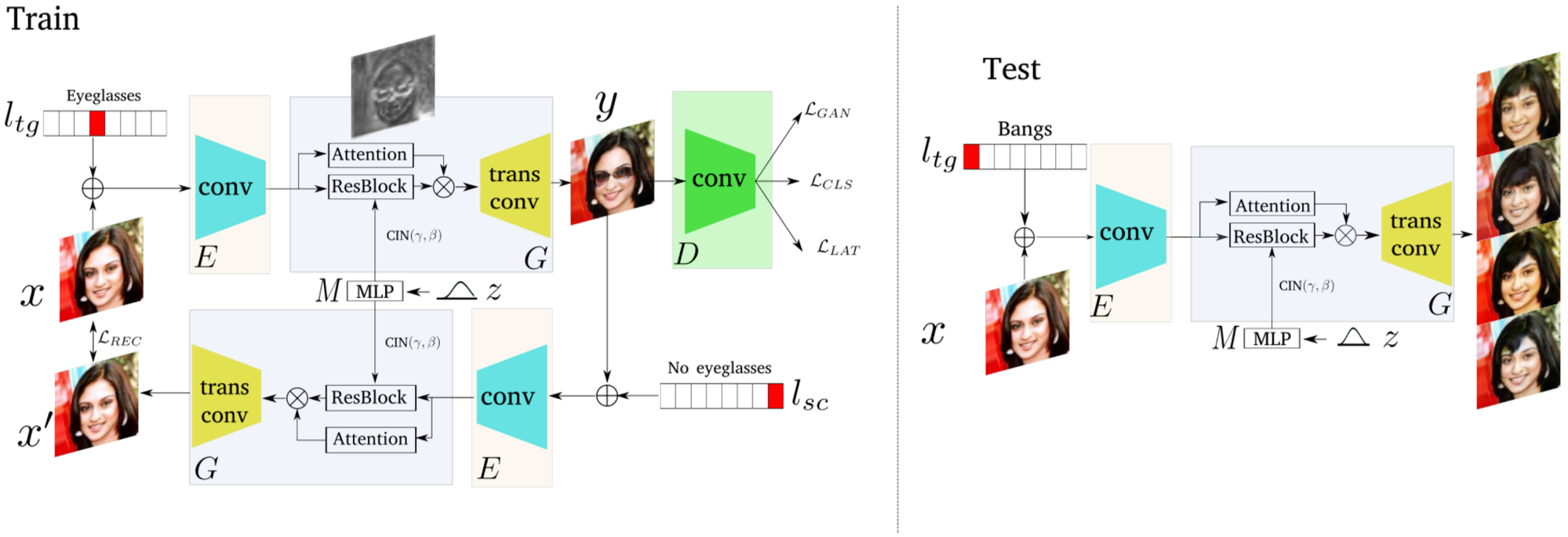
SDIT [ACM-MM 2019]
“Scalable and Diverse Cross-domain Image Translation”
単一ネットワークでScalabe(MUNITでいうところのマルチモーダル)かつDiverseなドメイン(マルチドメイン)変換をする。
StarGANv2 [CVPR2020]
“StarGAN v2: Diverse Image Synthesis for Multiple Domains”
生成画像の多様性とドメイン間のスケーラビリティを同時に満たす、単一フレームワークによるマルチドメイン変換。latent codeをstyle codeに変換するマッピングネットワークやGeneratorのデコーダ側でAdaINをStarGANに導入した。

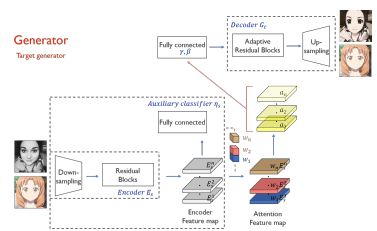
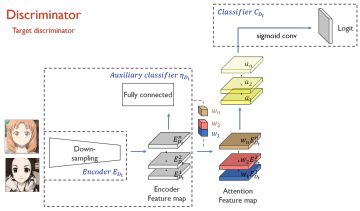
UGATIT [ICLR2020]
アニメ顔↔実画像の一対一の変換の学習。CycleGANの課題であった、形状変化に対しても対応できる。CAM分類器によるattention mapの作成、AdaLinという正規化によってコンテンツとスタイルの調和的な学習を実現。
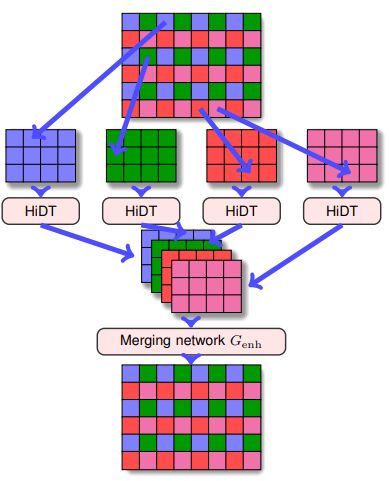
HiDT [CVPR2020]
“High-Resolution Daytime Translation Without Domain Labels”
筆者いわくUNIT→MUNIT→FUNIT→…の発展系。ドメインラベル不要で、風景画像の時間変化における連続的なドメインの変化を学習させる。ついでに高解像度なアップサンプリングも提案。Unsupervisedと思いきや、セグメンテーションマスクは必要である。
ALAE [CVPR2020]
“Adversarial Latent Autoencoders”
GAN+VAEでDisentanglementを学習し、例えば顔画像の高次元的な特徴・低次元的な特徴をともにパラメータとしてコントロールした画像を生成することができる。男→女、笑顔度合の変換など高速にできる。デモが優秀なので評価された感はある。
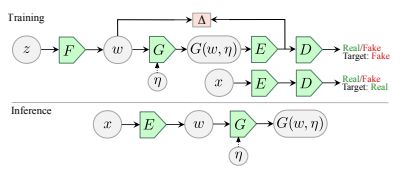
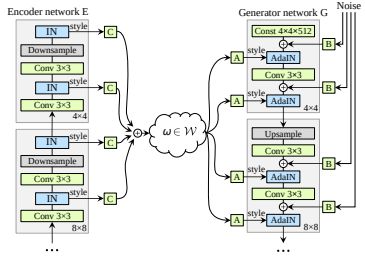
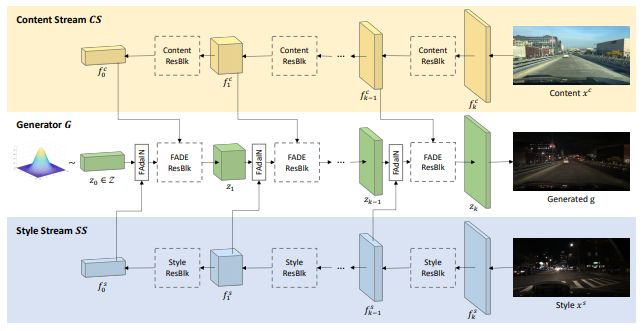
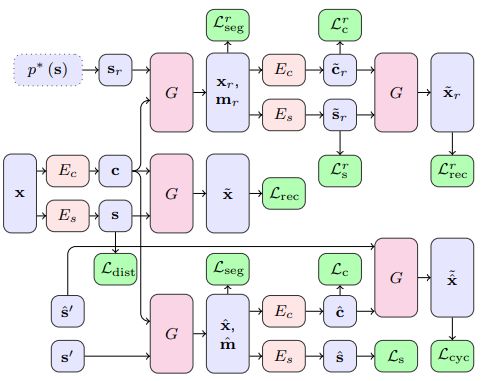
TUNIT [2020]
“Rethinking the Truly Unsupervised Image-to-Image Translation”
MUNITなどではドメインごとにデータセットを分けておく必要があるため完全なUnsupervisedとは言えない。大量の画像のみを与えるだけで、ドメインの分離をクラスタリングで行えるようにした。
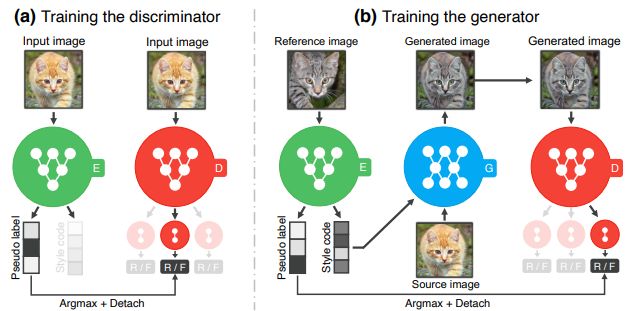
TSIT [ECCV2020]
“TSIT: A Simple and Versatile Framework for Image-to-Image Translation”
FADEブロック・FAdaINを導入した、シンプルなアーキテクチャで、cycle consistencyを使用せずにドメインの変換を学習することができる。一対一のドメイン変換から多対多のマルチモーダル変換まで幅広いタスクに対して適応できる。