GANの学習がうまくいかない
GANの学習はとても難しいといわれています。
- 学習が不安定で収束(ナッシュ均衡)しない
- 同じものしか生成しないMode collapseに陥る
- Discriminatorが圧勝し勾配消失が起きる
- GeneratorとDiscriminatorのバランスが悪く過学習する
- ハイパパラメータに敏感すぎる
通常のDeep Learningのロスであれば小さければ小さいほど学習が進んでいるといえます。基本的にはロスが一定の値まで小さくなり、頭打ちになると学習終了と判断することができます。しかしGANの学習では一方のロスがすぐに下がりきってしまうと学習失敗です。
GANではGeneratorとDiscriminatorのロスのバランスが命なのです。
GANのコードを実際に動かしてみたものの、対象のデータセットやハイパパラメータのチューニングに苦戦している人が多いと思います。今回は、私がGANの利用に行き詰まったときいつも参考にしているページを紹介します。
ここで紹介している内容を抑えておけばまずは十分でしょう。
GANの学習テクニック English/日本語
https://github.com/soumith/ganhacks
https://qiita.com/underfitting/items/a0cbb035568dea33b2d7
その他の学習を安定させるテクニック
- WGAN:Wasserstein距離を利用し勾配消失現象を克服
- WGAN-GP:さらにロスにペナルティ(Gradient Penalty)を導入
- hinge loss: realとfakeの乖離に上限を設定
- spectral normalizationなど
学習の様子を確認すること
TensorflowユーザでしたらtensorboardでGenerator LossとDiscriminator Lossの様子を必ずよーく観察しましょう。私の経験では、Discriminatorが強くなる傾向にあります。うまく学習できているときは、DiscriminatorがしっかりとGeneratorに騙されている状態が続きます。つまりDiscriminatorが本物と偽物のいずれも50%の確率で本物とみなす状態となります。このときDiscriminator Lossはln(0.5)+ln(1-0.5)≒-1.4付近の値を推移します。
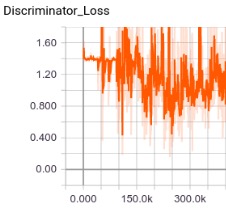
グラフががたがたと上下に揺れている状態が適切に学習できている証拠です。
一方でGeneratorLossの値が極端に大きくなる(5以上)と、もうほぼGeneratorには勝ち目がない状態です。Discriminatorが100%に近い割合で偽物を見抜いてしまいます。
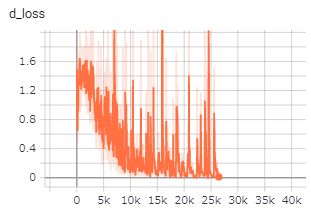
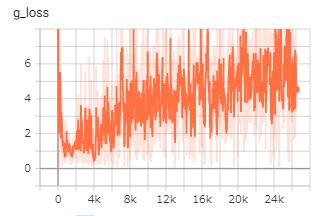
このときは、Discriminatorの学習を弱める工夫をほどこしましょう。上記の参照ページに記載があるように、Discriminatorのネットワークを小さくしたり、dropoutを多めに入れるなどの方法でGeneratorとのバランスを調整することができます。discriminatorの出力の結果を一定の割合でフリップすることで強制的にロスを生み出すというテクニックもあります。
また、一般的にはGeneratorとDiscriminatorの学習は交互に行っていきますが、Generator:Discriminatorを2:1の割合で学習するほうが学習が安定する事が多いです。
グラフの形状には必ず理由があります。一つ一つの数字を分析して改善を重ねていきましょう。以下のページも是非参考にしでみてください。
GANの基本的な知識や有名なアルゴリズム
https://elix-tech.github.io/ja/2017/02/06/gan.html
GAN関連Tensorflowで実装したモデルの一覧
https://github.com/hwalsuklee/tensorflow-generative-model-collections